Thread indexing is how each parallel thread determines which data element to process. Computing a unique global thread ID from threadIdx, blockIdx, and blockDim enables thousands of threads to safely access different array elements without conflicts. This way of connecting threads to data is very important for all kinds of GPU tasks. It works for simple things like adding numbers in an array, and also for more complex jobs like working with big matrices.
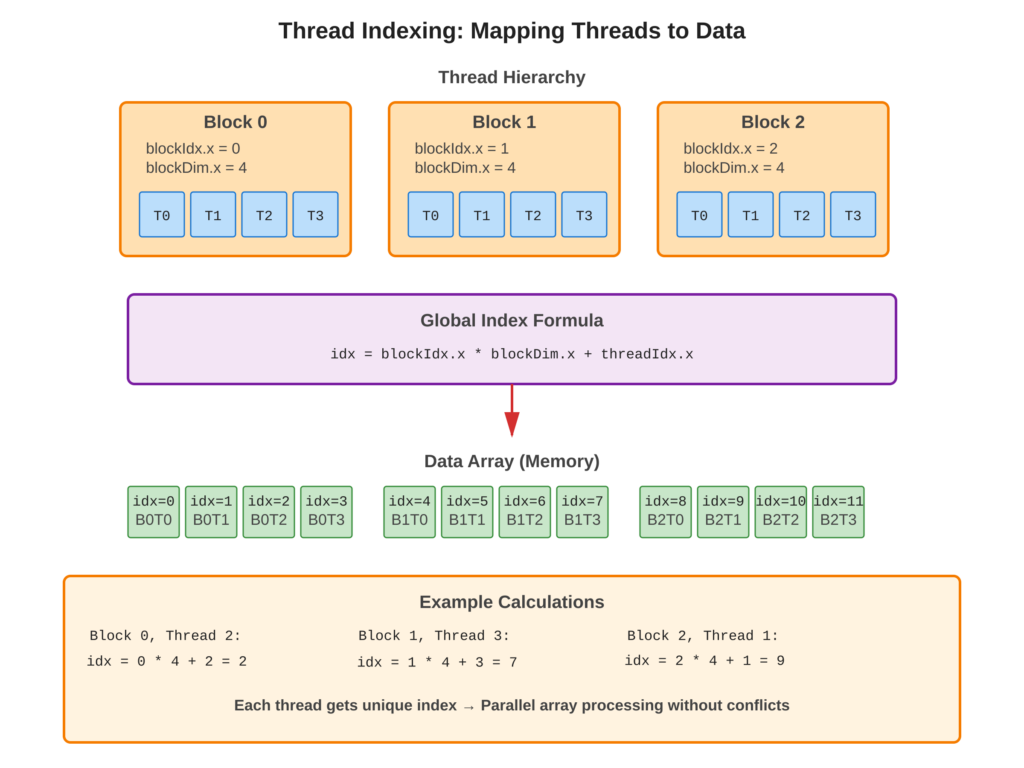
Refer to following diagram for visual guide to global index calculation
Core Concept
CUDA organizes threads in a hierarchy: grid, then blocks, and finally threads. But data arrays are usually flat or multi-dimensional. Each thread needs to know which part of the array it should work on. We use a formula to figure out the global index for each thread. The formula blockIdx.x * blockDim.x + threadIdx.x helps us find this index.
Here’s how it works:
blockIdx.xtells us which block we are in.blockDim.xtells us how many threads are in one block.threadIdx.xtells us the position of the thread within its block.
So, when you multiply the number of blocks before this one by the number of threads in each block and add your own thread’s position, you get the global index for that thread. This helps each thread know exactly which part of the array it should process.
Key Points
- Global Index: Unique identifier mapping thread to data element
- 1D Formula:
idx = blockIdx.x * blockDim.x + threadIdx.x - 2D Formula:
x = blockIdx.x * blockDim.x + threadIdx.x,y = blockIdx.y * blockDim.y + threadIdx.y - Bounds Checking: Always verify
idx < Nto prevent out-of-bounds access - Row-Major Order: For 2D arrays, compute
idx = y * width + x
Code Example
Kernel demonstrating 1D and 2D thread indexing for array access –
CUDA Implementation:
// 1D indexing - processing an array
__global__ void vectorDouble(float *data, int N) {
// Calculate global thread index
int idx = blockIdx.x * blockDim.x + threadIdx.x;
// Bounds check - crucial for safety
if (idx < N) {
data[idx] = data[idx] * 2.0f;
}
}
// 2D indexing - processing a matrix
__global__ void matrixAdd(float *A, float *B, float *C, int width, int height) {
// Calculate 2D indices
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
// Bounds check for both dimensions
if (col < width && row < height) {
// Convert 2D index to 1D array index
int idx = row * width + col;
C[idx] = A[idx] + B[idx];
}
}Launch Configuration:
// For 1D: N=10000 elements
int threadsPerBlock = 256;
int numBlocks = (N + threadsPerBlock - 1) / threadsPerBlock;
vectorDouble<<<numBlocks, threadsPerBlock>>>(d_data, N);
// For 2D: 1024x768 matrix
dim3 block(16, 16); // 256 threads per block
dim3 grid((width + 15) / 16, (height + 15) / 16);
matrixAdd<<<grid, block>>>(d_A, d_B, d_C, width, height);Usage & Best Practices
When to Use Each Pattern
- 1D indexing: Vectors, lists, simple array operations
- 2D indexing: Matrices, images, grids
- 3D indexing: Volumes, tensors, 3D simulations
Best Practices
- Always include bounds checking (
if (idx < N)) - Calculate grid size to cover all elements:
(N + blockSize - 1) / blockSize - Use row-major indexing for memory coalescing (will be covered later):
row * width + col
Common Mistakes
- Avoid: Forgetting bounds check (causes illegal memory access)
- Avoid: Using column-major indexing (poor performance)
Key Takeaways
Summary:
- Global thread index maps threads to unique data elements
- 1D formula:
blockIdx.x * blockDim.x + threadIdx.x - 2D formula: compute x and y separately, then combine
- Always bounds check:
if (idx < N)prevents errors - Calculate grid size to launch enough threads for all data
- Row-major indexing for efficient memory access
Quick Reference
1D Global Index:
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
// Safe to access data[idx]
}2D Global Index:
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
if (x < width && y < height) {
int idx = y * width + x; // Row-major
// Safe to access data[idx]
}3D Global Index:
int x = blockIdx.x * blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
int z = blockIdx.z * blockDim.z + threadIdx.z;
if (x < width && y < height && z < depth) {
int idx = z * (width * height) + y * width + x;
}Grid Size Calculation:
int numBlocks = (N + threadsPerBlock - 1) / threadsPerBlock;